5.05e+06 5.05e+06 ... 5.004e+06
array([5049992.781974, 5049761.125615, 5049529.469257, 5049297.812899,
5049066.156541, 5048834.500182, 5048602.843824, 5048371.187466,
5048139.531108, 5047907.874749, 5047676.218391, 5047444.562033,
5047212.905674, 5046981.249316, 5046749.592958, 5046517.9366 ,
5046286.280241, 5046054.623883, 5045822.967525, 5045591.311167,
5045359.654808, 5045127.99845 , 5044896.342092, 5044664.685734,
5044433.029375, 5044201.373017, 5043969.716659, 5043738.0603 ,
5043506.403942, 5043274.747584, 5043043.091226, 5042811.434867,
5042579.778509, 5042348.122151, 5042116.465793, 5041884.809434,
5041653.153076, 5041421.496718, 5041189.84036 , 5040958.184001,
5040726.527643, 5040494.871285, 5040263.214927, 5040031.558568,
5039799.90221 , 5039568.245852, 5039336.589493, 5039104.933135,
5038873.276777, 5038641.620419, 5038409.96406 , 5038178.307702,
5037946.651344, 5037714.994986, 5037483.338627, 5037251.682269,
5037020.025911, 5036788.369553, 5036556.713194, 5036325.056836,
5036093.400478, 5035861.74412 , 5035630.087761, 5035398.431403,
5035166.775045, 5034935.118686, 5034703.462328, 5034471.80597 ,
5034240.149612, 5034008.493253, 5033776.836895, 5033545.180537,
5033313.524179, 5033081.86782 , 5032850.211462, 5032618.555104,
5032386.898746, 5032155.242387, 5031923.586029, 5031691.929671,
5031460.273313, 5031228.616954, 5030996.960596, 5030765.304238,
5030533.647879, 5030301.991521, 5030070.335163, 5029838.678805,
5029607.022446, 5029375.366088, 5029143.70973 , 5028912.053372,
5028680.397013, 5028448.740655, 5028217.084297, 5027985.427939,
5027753.77158 , 5027522.115222, 5027290.458864, 5027058.802506,
5026827.146147, 5026595.489789, 5026363.833431, 5026132.177072,
5025900.520714, 5025668.864356, 5025437.207998, 5025205.551639,
5024973.895281, 5024742.238923, 5024510.582565, 5024278.926206,
5024047.269848, 5023815.61349 , 5023583.957132, 5023352.300773,
5023120.644415, 5022888.988057, 5022657.331698, 5022425.67534 ,
5022194.018982, 5021962.362624, 5021730.706265, 5021499.049907,
5021267.393549, 5021035.737191, 5020804.080832, 5020572.424474,
5020340.768116, 5020109.111758, 5019877.455399, 5019645.799041,
5019414.142683, 5019182.486325, 5018950.829966, 5018719.173608,
5018487.51725 , 5018255.860891, 5018024.204533, 5017792.548175,
5017560.891817, 5017329.235458, 5017097.5791 , 5016865.922742,
5016634.266384, 5016402.610025, 5016170.953667, 5015939.297309,
5015707.640951, 5015475.984592, 5015244.328234, 5015012.671876,
5014781.015518, 5014549.359159, 5014317.702801, 5014086.046443,
5013854.390084, 5013622.733726, 5013391.077368, 5013159.42101 ,
5012927.764651, 5012696.108293, 5012464.451935, 5012232.795577,
5012001.139218, 5011769.48286 , 5011537.826502, 5011306.170144,
5011074.513785, 5010842.857427, 5010611.201069, 5010379.544711,
5010147.888352, 5009916.231994, 5009684.575636, 5009452.919277,
5009221.262919, 5008989.606561, 5008757.950203, 5008526.293844,
5008294.637486, 5008062.981128, 5007831.32477 , 5007599.668411,
5007368.012053, 5007136.355695, 5006904.699337, 5006673.042978,
5006441.38662 , 5006209.730262, 5005978.073904, 5005746.417545,
5005514.761187, 5005283.104829, 5005051.44847 , 5004819.792112,
5004588.135754, 5004356.479396, 5004124.823037, 5003893.166679])


















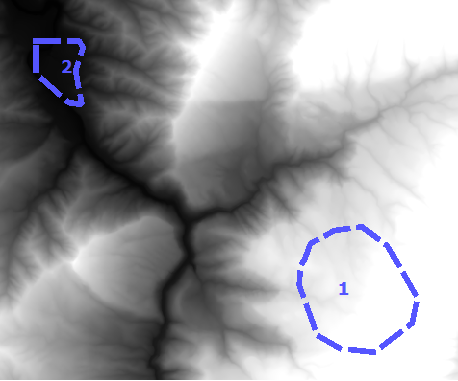










 dans la barre d’outils
dans la barre d’outils



